УПРОЩЕНИЕ СЛУЧАЙНЫХ ЛЕСОВ: КОМПРОМИСС МЕЖДУ
ИНТЕРПРЕТИРУЕМОСТЬЮ И ТОЧНОСТЬЮ
Шмелев Григорий Сергеевич
Студент 2-го курса
институт прикладной математики и компьютерных наук
ФГБОУ ВО «Тульский
государственный университет»
Россия, г. Тула
Аннотация. Я анализирую компромисс между сложностью модели и точностью
для случайных лесов (random
forests), разбивая деревья на отдельные правила классификации и
выбирая их подмножества. Также я показываю экспериментально, что уже нескольких
правил достаточно для достижения приемлемой точности, близкой к точности
исходной модели. Более того, результаты показывают, что во многих случаях это
может привести к более простым моделям, которые явно превосходят исходные.
Ключевые
слова: случайные леса, задачи
классификации, деревья решений
Введение
Случайные леса
(RF) [2] – это современный метод решения задач классификации и регрессии в
широком диапазоне областей. Этот метод также применяется к задачам, для которых
общепринято, что деревья решений являются неподходящими моделями, например, в
областях с непрерывными входными пространствами, для которых выровненные по оси
границы решения регулярных деревьев решений накладывают ограничение. Два
аспекта в индукции RF, кажется, имеют решающее значение для этой улучшенной
способности. Во-первых, из-за случайной выборки признаков и формирования
пакетов, приводящих к слегка смещенным распределениям классов, каждое дерево
решений выбирает слегка отличающиеся пороговые значения, шаблоны и условия
признаков. Это приводит к множеству альтернативных объяснений, увеличивая шансы
включения шаблонов с хорошим обобщением и одновременно избегая переобучения,
поддерживая определенную степень изменчивости. Во-вторых, используя группу
деревьев, чьи прогнозы объединяются путем голосования, случайные леса достигают
плавных границ принятия решений, что позволяет им решать проблемы, которые не
могут быть решены с помощью общего дерева решений для отдельных деревьев.
К сожалению,
одно из ключевых преимуществ деревьев решений, а именно их интерпретируемость,
сильно ограничено. Даже если каждое из деревьев можно понять и проанализировать
индивидуально, осмотр сотен или тысяч из них может легко подавить человека. В
этой работе меня интересует компромисс между эффективностью и
интерпретируемостью таких объединений. Я предлагаю преобразовать случайные леса
в правила классификации и исследовать упомянутый компромисс, выбрав
подмножества этих правил, используя различные подходы и эвристики, известные из
области индукции правил. В этом анализе я учитываю различные аспекты, такие как
охват и полнота, избегание избыточности и точность конечных моделей. Также я
утверждаю, что основанная на правилах стратегия имеет концептуальные
преимущества по сравнению с выбором подмножества деревьев. Во-первых, она
позволяет проводить более детальный анализ, поскольку можно исследовать эффект
добавления отдельных правил, а не целых деревьев, которые потенциально состоят
из большого числа правил. Во-вторых, основание выбора на деревьях, а не на
правилах, не приведет к лучшему компромиссу между эффективностью и
интерпретируемостью, поскольку каждое дерево покрывает все пространство
экземпляра и, следовательно, вносит большое количество избыточных правил в
модель.
Упрощение
случайных лесов путем выбора правил
Случайный лес
состоит из заранее определенного числа i
деревьев решений. Для построения отдельных деревьев учитывается только
подмножество доступных обучающих экземпляров (пакетирование) и атрибутов
(случайная выборка признаков), что гарантирует разнообразный набор деревьев.
Деревья случайных
лесов могут быть преобразованы в эквивалентный набор из d правил r: H
← B, рассматривая каждый путь от корневого узла до листа в качестве
правила предложения, где конъюнкция B содержит все условия, встречающиеся на
пути, и H предсказывает класс в листе. Для прогнозирования каждое правило
покрытия обеспечивает голос за класс в его голове. Обратите внимание, что
способ генерирования этих правил гарантирует, что каждый пример будет
охватываться ровно i правилами.
Чтобы оценить
качество отдельных правил, я полагаюсь на эвристику, обычно используемую при
обучении правилам (см., например, [1]). Эти эвристики фильтруют количество
истинных положительных, ложных положительных, истинных отрицательных и ложных
отрицательных значений, предсказанных правилом, в эвристическое значение h, обычно ∈ [0, 1]. Среди
эвристик, которые я использую, есть точность или достоверность,
которая часто использовалась, несмотря на ее склонность к переобучению, а также
отзывчивость, которая, как ожидается, будет хорошо работать в условиях, когда
используется голосование. Кроме того, я использую параметризацию m-оценки,
которая оказалась одной из наиболее эффективных эвристик в обучении правилам.
Для выбора подмножества n < d
правил среди всех d
правил, которые были извлечены из RF, используются следующие стратегии. (1)
Лучшие правила: лучшие n правил в соответствии с указанной
эвристикой включены в подмножество. (2) Взвешенное покрытие: аналогично
(1), но после выбора правила, вес покрываемых им экземпляров делится пополам.
Повторная проверка оставшихся правил на основе новых весов обеспечивает равный
охват данных обучения.
Эксперименты
Для моих
экспериментов я натренировал случайный лес со 100 деревьями на наборе обучающих
данных, извлек n правил относительно стратегий, упомянутых выше, и
оценил их точность на тестовом наборе.
В качестве
первого шага я применил свой метод к синтетическому набору данных, задача
которого состоит в приближении косой границы решения в двумерном пространстве
(рис. 1). Результаты показывают, что выбор наилучших правил в соответствии с
определенной эвристикой (в данном случае m-оценкой) дает набор
избыточных правил, охватывающих в основном однородную область. Напротив,
взвешенное покрытие выбирает более разнообразные правила, более равномерно
покрывая пространство экземпляра. Это приводит к более точному приближению
исходной границы решения.
На рис. 2
показано поведение различных стратегий выбора правил в наборе данных о раке
молочной железы из хранилища UCI (полученном путем 10-кратной
перекрестной проверки). В частности, взвешенное покрытие, использующее m-оценку или напоминание
(recall),
работает хорошо, достигая базовой эффективности использования всех правил уже
после выбора около 20 (отзывов) или 60 (m-оценок) правил. При
использовании около 20% всех правил можно наблюдать явное улучшение. Интересно,
что производительность также может снова упасть (m-оценка). Напоминание
(recall)
кажется более надежным, даже при использовании лучшей стратегии правил. Это
также подход с самым резким увеличением охвата. Результаты для других наборов
данных (не показаны здесь) демонстрируют аналогичные эффекты.
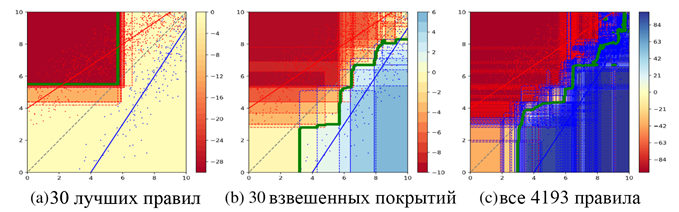
Рисунок 1 - Синтетические данные с 800 красными и 200 синими
экземплярами, как правило, распределены по соответствующим линиям.
Прямоугольники обозначают правила, их цвета обозначают разницу между синими и
красными голосами. Зеленая линия визуализирует границы решения.
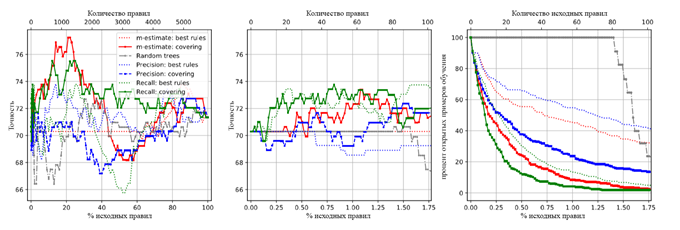
Рисунок 2 - Точность данных набора рака молочной железы
с использованием до d правил (слева) или до 100 правил (в середине). Для
последнего также показывается доля непокрытых тестовых экземпляров (справа).
Подход «Случайные деревья» добавляет все правила случайным образом выбранного
дерева одновременно.
Заключение
Я предложил
методику упрощения случайных лесов на основе выбора подмножества правил. Как
показывают предварительные результаты, высокая прогнозирующая эффективность
достижима уже с помощью нескольких правил, часто даже явно превосходящих
базовые показатели. Результаты показывают, что наибольший потенциал для
улучшения заключается в стратегии выбора правил.
Список использованной литературы:
1. Fürnkranz, J. Foundations of Rule Learning / J. Fürnkranz,
D. Gamberger, N. Lavrač
– 1-e изд. – Берлин: Springer-Verlag Berlin Heidelberg, 2012. – 334 с.
2. Random forest [Электронный ресурс] //
Wikipedia The Free Encyclopedia – Режим доступа: https://en.wikipedia.org/wiki/Random_forest (дата обращения:
09.11.2019)
Сведения
об авторе:
Шмелев Григорий Сергеевич – студент 2-го курса
института прикладной математики и компьютерных наук ФГБОУ ВО «Тульский
государственный университет».
OVERSIMPLIFYING
RANDOM FORESTS: COMPROMISE BETWEEN INTRICACY AND PRECISION
Shmelev G.S.
Abstract. I dissect a compromise between intricacy of a model
and precision or random forests by separating trees in singular arrangement regulations
and choosing a subset. I indicate that effectively a tad bit of rules are
adequate to accomplish a worthy precision near that of the initial model. Also,
my outcomes demonstrate that by and large, this can bring more straightforward
models that beat the initial ones.
Keywords: random forests, classification problems, decision
trees
References:
1. Fürnkranz, J. Foundations of Rule Learning / J. Fürnkranz,
D. Gamberger, N. Lavrač
– 1 ed. – Berlin: Springer-Verlag Berlin Heidelberg,
2012. – 334 p.
2. Random forest [Electronic
resource] // Wikipedia The Free Encyclopedia – Access mode:
https://en.wikipedia.org/wiki/Random_forest (access
date: 09.11.2019)